Linux内核程序员几乎每天都在和各种问题互相对峙:
内核崩溃了,需要排查原因。
系统参数不合适,需要更改,却没有接口。
改一个变量或一条if语句,就要重新编译内核。
想稍微调整下逻辑却没有源码,没法编译。
解决每一类问题都需要消耗大量的时间,特别是重新编译内核这种事情。于是,每一个Linux内核程序员或多或少都会掌握一些Hack技巧,以节省时间提高工作效率。
然而,自己Hack内核非常容易出错,稍不留意就会伤及无辜(panic,踩内存),然后你会陷入没完没了的细节,比如查找页表就够折腾。
俗话说工欲善其事,必先利其器,临渊羡鱼,不如退而结网。
但是如果你使用现成的工具,就会发现有时候工具很难扩展。自己需要的边缘小众功能往往并不提供,你依然需要自己动手但却又无从下手。
怎么办?
为何不把二者结合呢?
本文将通过几个简单的小例子,描述如何综合systemtap,crashgdb,/dev/mem,内核模块等技术排查以及解决现实中的Linux问题。
关于前置知识本文不想花太多笔墨在前置知识上,本文默认读者已经了解systemtap,crashgdb等工具的基本用法。作为Linux内核开发者,这些工具的熟练使用是必须的。
如果需要这些知识,自行百度或者Google(有条件的话),会得到更好的答案。其中每一个细节都可以单独写一篇文章甚至一本书。
但还是要说一点关于/dev/mem的话题。
/dev/mem几乎总是被宣称为作为整个物理内存映像可以被mmap到进程地址空间,很多人确实将/dev/mem设备文件mmap到了自己的程序,然而却几乎一无所得。这不是程序员的错,毕竟作为一个平坦的内存地址空间,/dev/mem的内容看起来没有任何结构,一般DIY的程序根本就无力解析它。
/dev/mem是个宝藏,它暴露了整个内存,但是只有你拥有强大的分析能力时,它才是宝藏,否则它只是一块平坦的空间,充满着0或1。所有的内核实时数据均在/dev/mem中,找到它们才有意义,但找到它们并不容易。
crashgdb工具会把这件事情做得很好。本文后面将侧重于crash工具,gdb与此类似。
crash不光可以用来分析调试已经死掉的Linux尸体的vmcore内存映像,还可以用来分析调试活着的LinuxLive内存映像,比如/dev/mem和/proc/kcore。同样都是内存映像,调试活着的内存映像显得更加有趣些。本文的例子将无一例外地描述这个方面的操作步骤和细节。
现在让我们开始。
使/dev/mem可写这个例子是第一步,也是继续下面所有例子的前提。
首先,我们执行crash命令,调试/dev/mem内存映像:
[root@localhost~]stap-g-e'("devmem_is_allowed").return{$return=1}'在上述stap命令保持的情况下,退出crash并再次运行,此时我们便将可以完全读写/dev/mem了,如果说依然发生内存不可写的情况,那便是受到了页表项的约束,这个我们后面会谈。
我们并不想让那个stap命令一直运行在那里,我们不希望通过crash写内存这个操作依赖一个不能退出的stap命令,所以第一步,我们将直接修改devmemisallowed函数本身!
我们先反汇编它:
crashdis-sdevmem_is_allowedFILE:arch/x86/mm/:583578**Accesshastobegiventonon-kernel-ramareasaswell,thesecontainthePCI580*mmioresourcesaswellaspotentialbios/*/582intdevmem_is_allowed(unsignedlongpagenr)583{584if(pagenr256)585return1;586if(iomem_is_exclusive(pagenrPAGE_SHIFT))587return0;588if(!page_is_ram(pagenr))589return1;590return0;591}crash非常简单的逻辑,我想我们可以很快完成该函数的二进制修改。
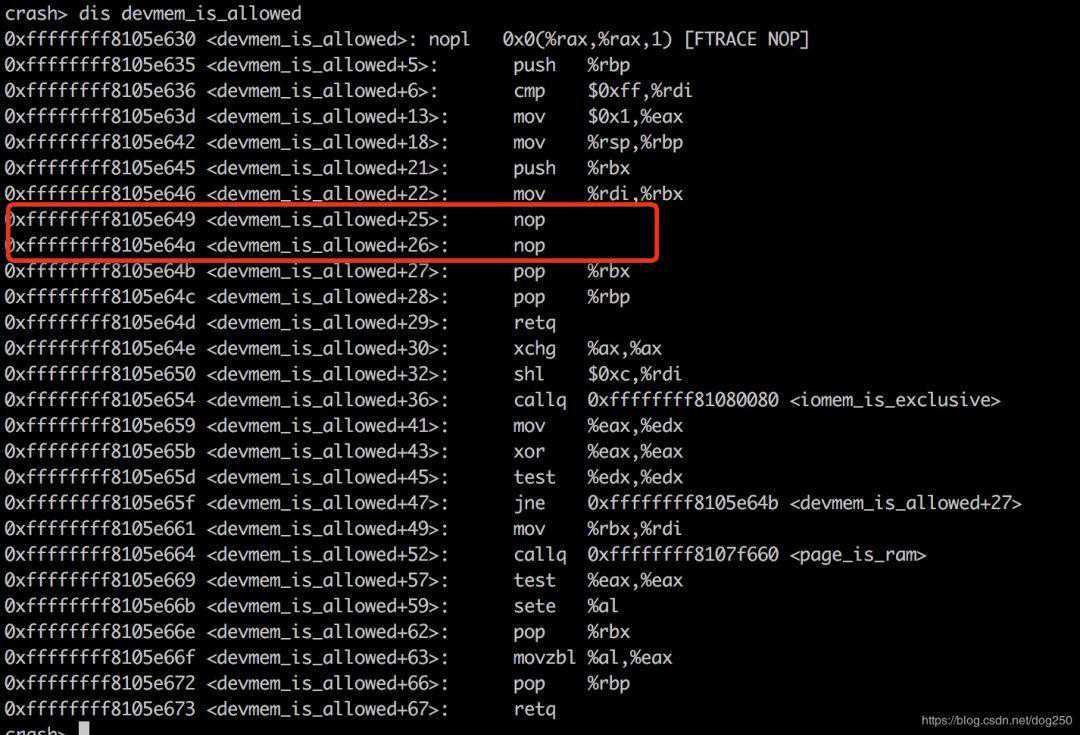
让我们看一下它的汇编码,并且注意到下图红色框里的细节:
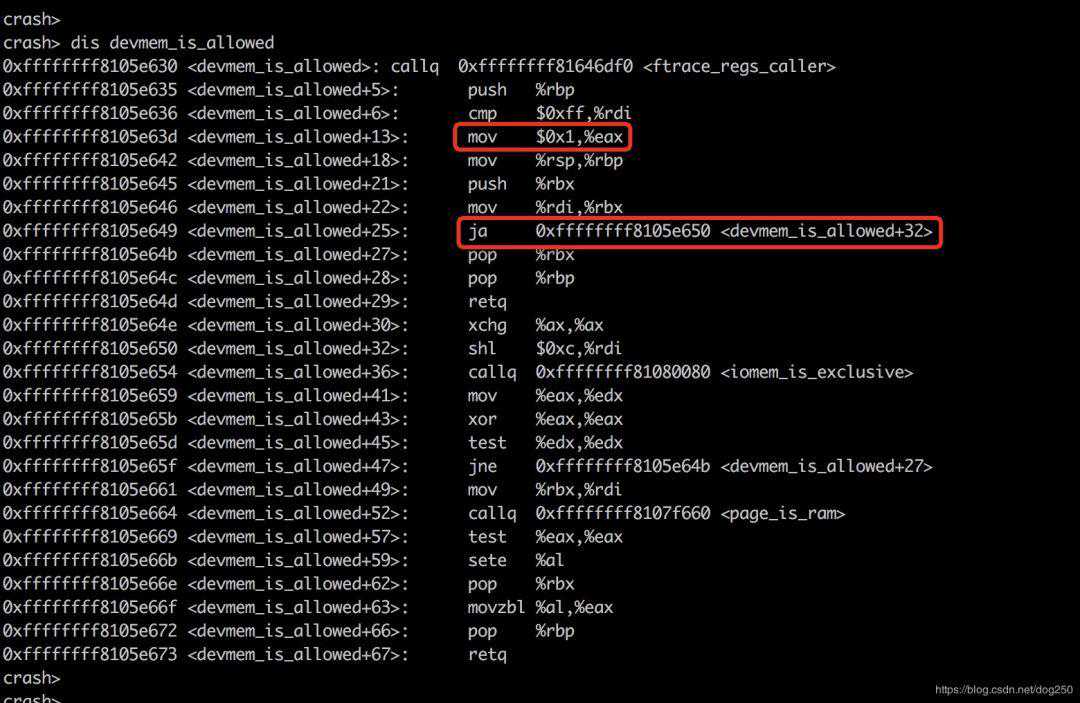
我们只要将jaxxx处的指令改成nop序列即可绕开这个跳转,即修改0xffffffff8105e649地址处的2个字节的值:
crashwr-160xffffffff8105e6490x9090
当然,比这个更直接的方法是直接重写这个函数,仅仅执行两个指令,mov$0x1,%eax和retq。但是很遗憾,使用crash命令完成这个修改难度极大,我们仔细缕一下:
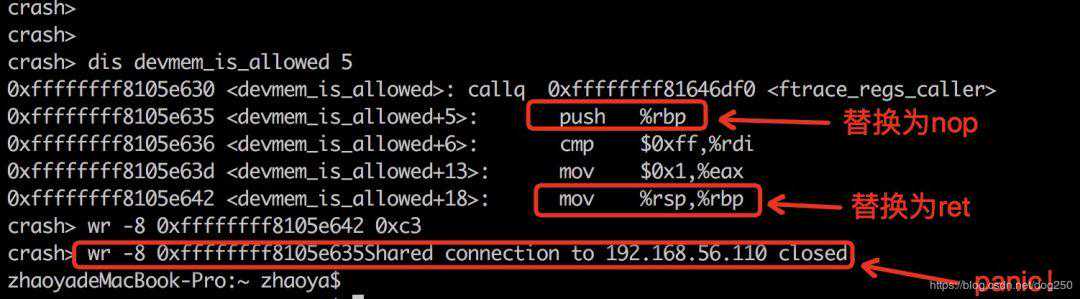
无论先替换nop还是先替换ret,均会破坏栈帧,造成返回地址错误从而panic:

除非同时原子替换二者(这在crash工具中几乎不可能)。更安全的替换方案是在crash外部去替换,比如写一个内核模块。先将crash查询到的地址记录下来:

随后编写模块,修改两个地址的值:
defineTCP_INIT_CWND10
然而宏并非变量,宏是在编译期就被替换的。
为了确认这宏定义值,我们编写一个简单的packetdrill脚本:
////(,SOCK_STREAM,IPPROTO_TCP)=30.000bind(3,,)=00.000listen(3,1)=00.000S0:0(0)win32792mss1000,sackOK,nop,nop,nop,:0(0):1(0)(3,,)=40.0%{printtcpi_snd_cwnd}%0.0write(4,,20000)=200005.0.1:1(0)ack1win257sack1001:3001,nop,nop运行它:
[root@localhostsack]pdrill./_usecs=100005
通过利用crash工具,修改TCP初始拥塞窗口非常简单。
修改TCPTimewait时间很多人遭遇过TCPTimewait过多的问题,一个主动断开的连接要维持60秒的Timewait状态(Linux系统),这在现代高速网络环境下已经不再必要。我们想把这个值调小,但遗憾的是,这个值在Linux内核中同样是是以宏定义存在的,无法调整。
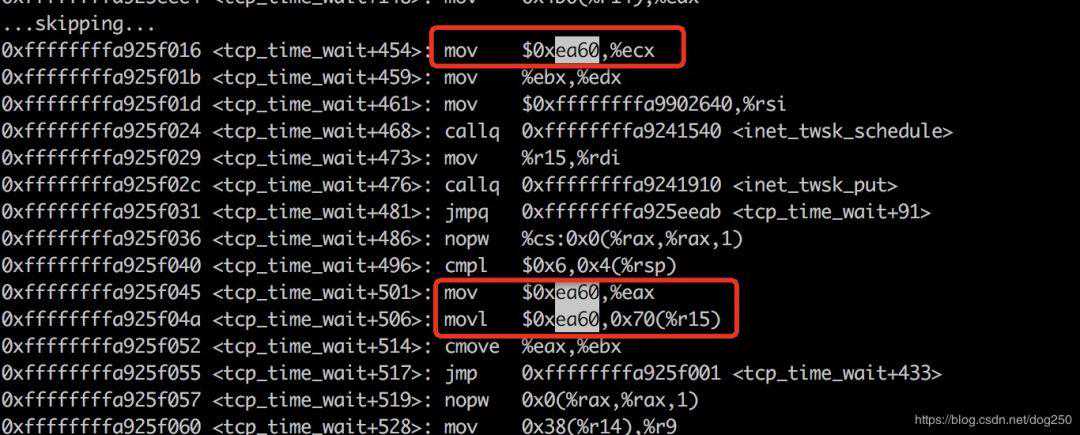
和修改TCP初始拥塞窗口方法一致,不同的是tcptimewait函数的复杂度要远高于tcpinitcwnd函数,不过大同小异,TCPTIMEWAITLEN和TCPINITCWND在同一个地方被定义:
无可写标志!!PAGEPHYSICALMAPPINGINDEXCNTFLAGSffffe06f80ee1bc03b86f0000011fffff00000400reservedcrash
注意到,3b8000e1表明该页表项指向的页面是不可写的!
我们需要修改页表项,而这个很容易,注意以下的关系:
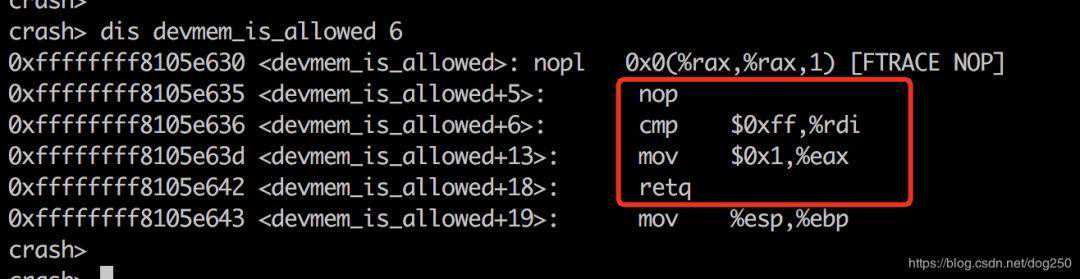
我们只需要写物理内存0x3c413a30即可:
crashrd-p3c413a303c413a30:000000003b8000e1;.crashwr-p3c413a30000000003b8000e3crash
此时,再次确认之前写失败的vtop结果:
PTEPHYSICALFLAGS3b8000e33b800000(PRESENT|RW|ACCESSED|DIRTY|PSE)includelinux/(*pf)(void);staticint__initflushtlb_init(void){//从/proc/kallsyms获取flush_tlb_all的地址并调用.pf=0xffffffffa8c7a040;pf();//不要真正加载return-1;}staticvoid__exitflushtlb_exit(void){}module_init(flushtlb_init);module_exit(flushtlb_exit);MODULE_LICENSE("GPL");我们发现,只要刷一遍TLB,crash中读取的页表项PTE就会重新还原为不可写。
出现该问题的内核编译时有两个选项CONFIGPHYSICALSTART和CONFIGPHYSICALSTART,crash的manual中有关于此的描述:
我们确认下当前写失败的内核的config文件配置:
CONFIG_PHYSICAL_START=0x1000000CONFIG_PHYSICAL_ALIGN=0x200000
与此同时,该内核的flushtlball并非简单操作RC4寄存器这么简单。
我们不再指望使用crash直接修改内存,退一步,让crash作为我们的信息查询工具起作用,剩余的内存写操作让我们自己写内核模块来做。
依然以修改TCP初始拥塞窗口为例,我们要改两个地方:
改页表项,让tcp_init_cwnd函数指令可写。
改tcp_init_cwnd函数硬编码的指令操作数。
分两步走,先找到页表项并通过ptov命令得到它的虚拟地址(所有OS级别的写内存都基于虚拟地址进行):
再找需要修改的指令地址和值:
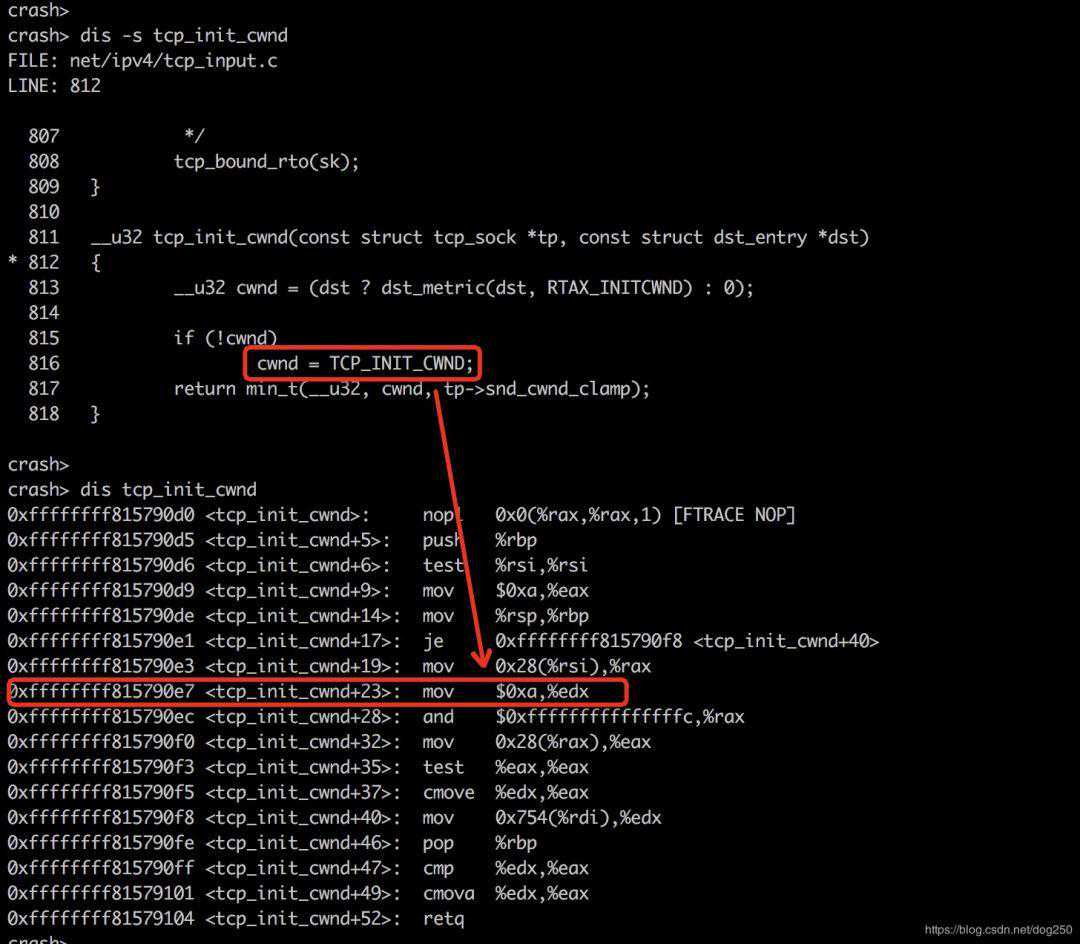
我们依据这些值编写内核模块:
/
然后在crash中找到它:
crashps|:7166COMMAND:""TASK:ffff9e6bf66f8000[THREAD_INFO:ffff9e6bcb0ec000]CPU:0STATE:TASK_INTERRUPTIBLE
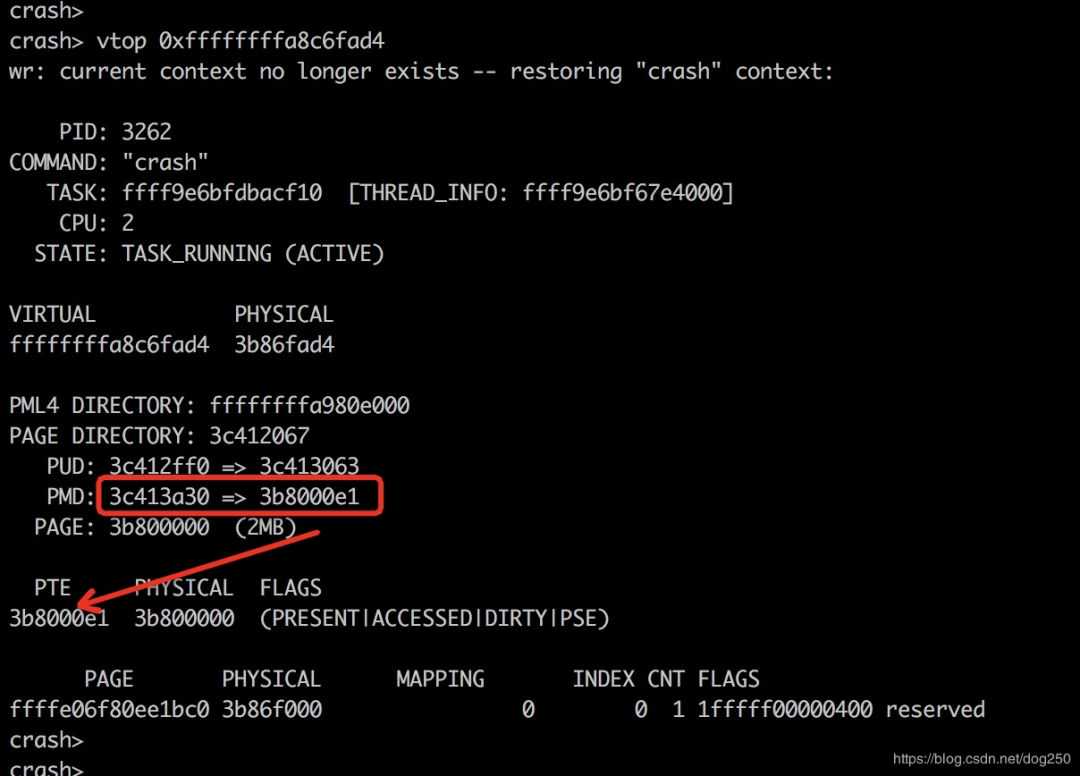
我们的目标是修改变量a的值,因此我们要定位该进程的用户态堆栈。
注意,此时getchar已经在内核空间等待了,所以bt命令只是内核栈,用户占还需要我们自己来找,我们从进程的task_struct结构体里寻找用户堆栈的蛛丝马迹:
crashtask_structffff9e6bf66f8000structtask_struct{state=1,stack=0xffff9e6bcb0ec000,usage={counter=2},flags=4202496,sp0=538288128,sp=538287176,usersp=9480,我们就从usersp=9480开始找吧:
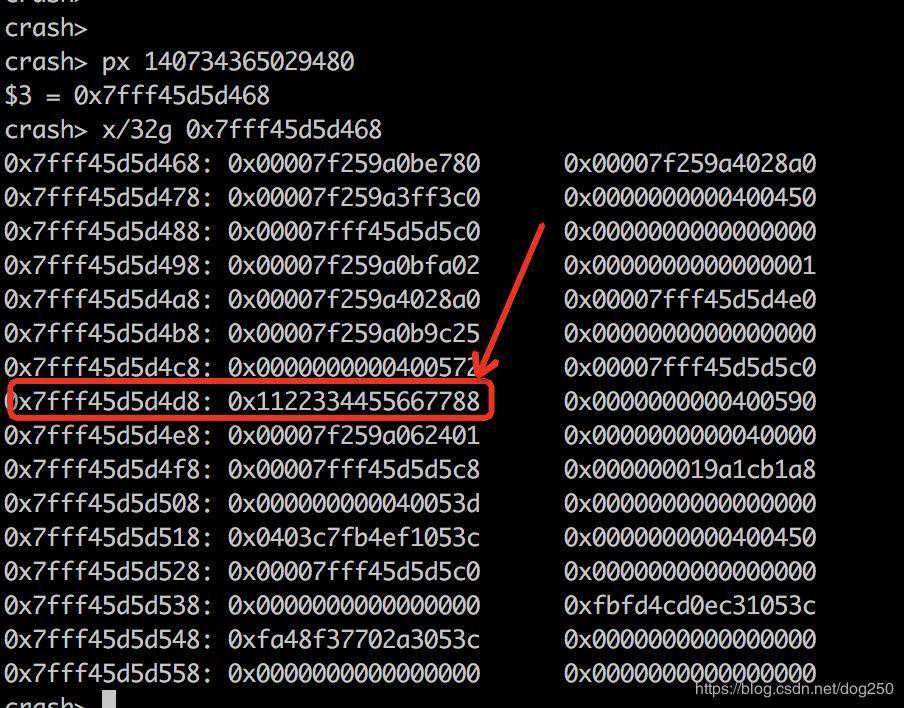
现在修改它:
crashwr-u-640x7fff45d5d4d80xaabbccdd99887700
然后在运行的终端敲回车:
[root@localhostmod]includelinux//=1234;module_param(condition,uint,0644);wait_queue_head_twaitq;staticint__initDs1_init(void){longmagic=0x22334455667788;condition=0x1234;printk("condition:%lumagic:%lu%p\n",condition,magic,waitq);init_waitqueue_head(waitq);//此处没有任何人会将condition设置为123,因此insmod会一直等待,进而D住wait_event(waitq,condition==123);return0;}staticvoid__exitDs1_exit(void){}module_init(Ds1_init);module_exit(Ds1_exit);MODULE_LICENSE("GPL");然后我们试着加载这个模块。很不幸,卡住了,即便是kill-9也无法杀掉它。很显然,它D住了:
现在,我们如何将其从D状态激活呢?下面我们用crash工具试试看。我们的目标有3步:
找到insmod进程。
修改内核模块里的condition变量的值为希望的123。
唤醒insmod睡眠在的wait队列。
我们一步一步来。先找到insmod进程:
crashps|:9074COMMAND:"insmod"TASK:ffff88003a3e3de0[THREAD_INFO:ffff880022a2c000]CPU:0STATE:TASK_UNINTERRUPTIBLE0[ffff880022a2fca8]__scheduleatffffffff81639b5d2[ffff880022a2fd20]init_moduleatffffffffa00370bb[main4]4[ffff880022a2fd90]load_moduleatffffffff810e9f3e6[ffff880022a2ff80]system_call_fastpathatffffffff81645189RIP:00007f313239a1c9RSP:00007ffdbeea5578RFLAGS:000102162[ffff880022a2fd20]init_moduleatffffffffa00370bb[main4]
我们就在地址0xffffffffa00370bb前面某个地方找找看。之所以在前面找是因为condition变量的操作语句在执行流调用下一个函数之前,所以还在上一个栈帧上:

当然,更直接的,还可以直接反汇编Ds1_init函数,很容易从内核栈上获取它的位置:
现在很明确,方法有两个:
修改cmpl语句,将123,即0x7b改成0x1234。
修改condition变量位置的值,改成0x7b,即123。
我选择方法2(宁改数据不改指令,万一碰到指令不可写又要改页表项):
crashrd-320xffffffffa0146000ffffffffa0146000:00001234crashwr-320xffffffffa01460000x0000007bcrashcrashwaitq0xffffffffa0370260PID:9074TASK:ffff88003a3e3de0CPU:1COMMAND:"insmod"crash
现在condition的值已经是123了,接下来最后一步,唤醒insmod的睡眠队列wait。再看上面的反汇编:
注意到地址0xffffffffa0146260,作为函数preparetowait的参数,它就是等待队列waitq。我们确认一下:
crashwait_queue_head_ttypedefstruct__wait_queue_head{spinlock_tlock;structlist_headtask_list;}wait_queue_head_t;SIZE:24crashwait_queue_head_t0xffffffffa0146260structwait_queue_head_t{lock={{rlock={raw_lock={{head_tail=131074,tickets={head=2,tail=2}}}}}},task_list={next=0xffff880022a2fd40,prev=0xffff880022a2fd40}}0xffff880022a2fd40作为两枚listhead指针,链入的正是waitqueuet,我们可以再次确认:

其中确认waitqueuet对象时将list减去3*8这个偏移是可以用crash工具的**计算出来的。
现在,是时候写一个内核模块来唤醒D进程了:
includelinux/__initwake_init(void){wait_queue_head_t*wait=0xffff880022a2fd28;wake_up(wait);//并不加载,wakeup后即退出。return-1;}staticvoid__exitwake_exit(void){}module_init(wake_init);module_exit(wake_exit);MODULE_LICENSE("GPL");编译加载,加载,效果如下:
[root@localhostmod]ps-elf|grep[i]nsmod[root@localhostmod]#
这就完成了我们拯救D进程的演示,但是注意,拯救D进程没有通用的方法,即便是成功将其从D状态救出,也依然要确认资源依赖,解除资源依赖后尽快调用do_exit。
结语以上只是抛砖引玉般结合crash,stap以及内核模块分析了几个简单的实例,如果继续下去,还会有非常多类似的例子以及更为复杂更为有趣的案例供我们去分析或者把玩,这将给我们带来无穷无尽的快乐。
但是限于篇幅,本文只能在此点到为止。本文的宗旨在于,通过这些简单有趣的实例,让我们理解工具的使用方法以及使用这些工具的重要性。
与此同时,在我们日常分析解决Linux内核问题时,如何使用工具并不是核心,工具始终只是一个让你的工作效率更高的锦上之花,真正干货的背后永远都是对操作系统理论以及对Linux内核本身的理解和掌握,否则,工具掌握得再熟练也只能是个熟练工。